如何用 Python 自动翻译 Markdown 文档

很多朋友问我这个网站多国�语言是怎么做的 ?
Docusaurus 本身就支援 i18n,但是比较麻烦的是不同的语言对应的就是不同的 md 文档,当然也可以直接将繁中的 md 档内容贴到 google 翻译,然后再将翻译完成的内容贴回简中的 md 档,但身为工程师是不允许这样做的...
Google Translate API
其实正解应该是使用 Google Translate API,不过这个服务是付费的,而且需要先注册 GCP 帐号,并不符合我不想付钱的需求
Selenium 执行 Google 翻译网页
回到文章最前面
可以直接将繁中的 md 档内容贴到 google 翻译,然后再将翻译完成的内容贴回简中的 md 档
如果写成自动化程式直接执行,问题是不是就解决了 ?
Selenium 是最直觉想到的工具,我们这里使用的 Selenium Python 的版本
前置作业
- 电脑安装 Python 环境
- 下载 webdriver 对应电脑 chrome 版本
然后我们找到了 google 翻译的网址
https://translate.google.com.tw/?sl=zh-TW&tl=zh-CN&op=translate
其中sl=zh-TW => 代表来源是繁中,tl=zh-CN => 代表要翻译成简中,只需要更改这两个参数,就可以更改要翻译的语言
再来要定位 input 和 output
input 比较简单,整个页面只有一个 textArea,所以也不需要特别定位
output 就比较麻烦,先按 F12,叫出 chrome dev tools (其他的浏览器也有对应的功能,这里用 chrome),然后在翻译的地方随便打几个字
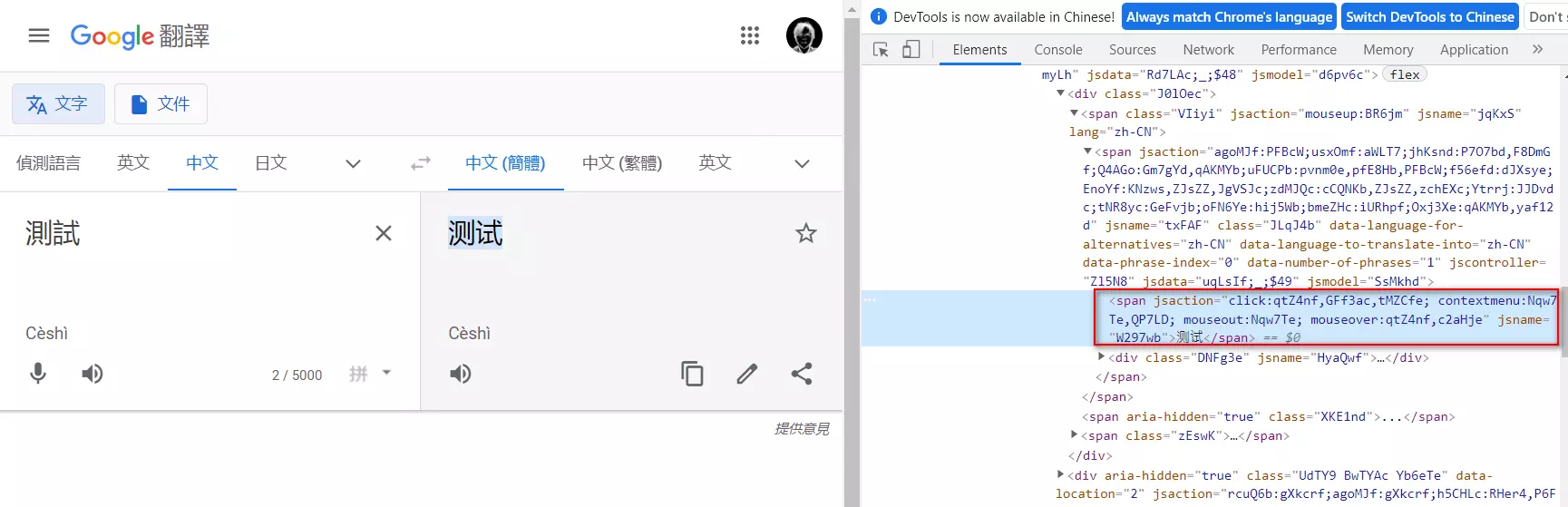
在对应的 span 按右键,选「Copy」再选「Copy Xpath」
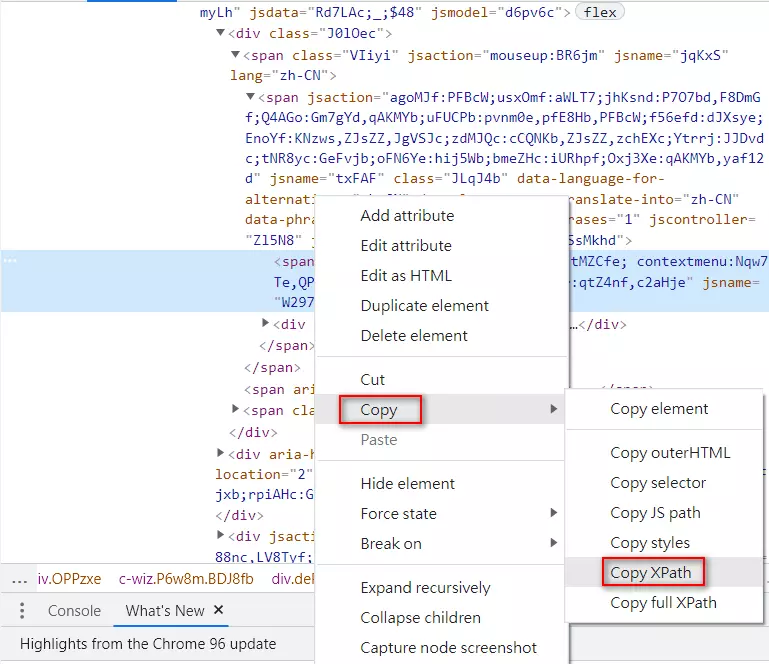
就会取得像以下的值
//*[@id="yDmH0d"]/c-wiz/div/div[2]/c-wiz/div[2]/c-wiz/div[1]/div[2]/div[2]/c-wiz[2]/div[5]/div/div[1]/span[1]/span/span
开始写程式
安装 Selenium
pip install selenium
设定的部份填上自己电脑环境的资料
- chrome_driver_path: 刚才下载 webdriver 后存放的路径
- source_path: 翻译档案来源路径
- target_path: 翻译后档案存放路径
- translate_files: 要翻译的档案,可一次设定多个档案
- source_language: 翻译来源语言
- target_language: 翻译后语言
- target_xpath: 刚才查到的 XPath
- sleep_second: 避免执行太频繁,sleep 的秒数
完整程式码如下
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
# Setting
chrome_driver_path = "C:/software/chromedriver_win32/chromedriver.exe"
source_path = 'C:/project/havocfuture/src/pages/'
target_path = 'C:/project/havocfuture/i18n/zh-hans/docusaurus-plugin-content-pages/'
translate_files = ['a.md', 'b.md']
source_language = 'zh-TW'
target_language = 'zh-CN'
target_xpath = '//*[@id="yDmH0d"]/c-wiz/div/div[2]/c-wiz/div[2]/c-wiz/div[1]/div[2]/div[2]/c-wiz[2]/div[5]/div/div[1]/span[1]/span/span'
sleep_second = 1
## 翻译 function
def translate_text(_text):
url = "https://translate.google.com.tw/?sl=" + source_language + "&tl=" + target_language + "&op=translate"
options = webdriver.ChromeOptions()
options.add_argument("--no-sandbox")
options.add_argument("--headless")
options.add_argument('--disable-infobars')
options.add_argument('--blink-settings=imagesEnabled=false')
driver = webdriver.Chrome(executable_path=chrome_driver_path, options=options)
driver.get(url)
time.sleep(sleep_second)
input_element = driver.find_element_by_tag_name('textArea')
input_element.send_keys(_text)
time.sleep(sleep_second)
result_elements = driver.find_element_by_xpath(target_xpath)
result = result_elements.text
time.sleep(sleep_second)
driver.close()
return result
# 回圈翻译档案
for x in translate_files:
source_file_path = source_path + x
target_file_path = target_path + x
f1 = open(source_file_path, 'r', encoding="utf-8")
source_content = f1.read()
f1.close()
f2 = open(target_file_path, 'w', encoding="utf-8")
target_content = translate_text(source_content)
f2.write(target_content)
f2.close()
这样只要设定完后,执行后就可以一口气就 Markdown 文档翻译完且放在对应的路径下了
已知问题
google 翻译页面不能翻译超过 5000 字元,如果档案太大是会翻译失败的,如果有太大档案的翻译需求,看来还是要乖乖付钱去用 google translate API
googletrans
名字取得很像 google 官方的工具,但实际上是第三方的 lib,我是写完上面使用 selenium 才发现这个工具的,怎么使用可以参考官方文件,就不再多说
要注意的是直接用 pip install 的版本 3.0.0 我实测是不能用的,估计是 google 有改版,但原作者没有继续维护下去,改安装社群修改过后的版本
pip install googletrans==3.1.0a0
实测 3.1.0a0 这个版本可以正常使用没有问题
