如何用 Python 自動翻譯 Markdown 文檔

很多朋友問我這個網站多國語言是怎麼做的 ?
Docusaurus 本身就支援 i18n,但是比較麻煩的是不同的語言對應的就是不同的 md 文檔,當然也可以直接將繁中的 md 檔內容貼到 google 翻譯,然後再將翻譯完成的內容貼回簡中的 md 檔,但身為工程師是不允許這樣做的...
Google Translate API
其實正解應該是使用 Google Translate API,不過這個服務是付費的,而且需要先註冊 GCP 帳號,並不符合我不想付錢的需求
Selenium 執行 Google 翻譯網頁
回到文章最前面
可以直接將繁中的 md 檔內容貼到 google 翻譯,然後再將翻譯完成的內容貼回簡中的 md 檔
如果寫成自動化程式直接執行,問題是不是就解決了 ?
Selenium 是最直覺想到的工具,我們這裏使用的 Selenium Python 的版本
前置作業
- 電腦安裝 Python 環境
- 下載 webdriver 對應電腦 chrome 版本
然後我們找到了 google 翻譯的網址
https://translate.google.com.tw/?sl=zh-TW&tl=zh-CN&op=translate
其中sl=zh-TW => 代表來源是繁中,tl=zh-CN => 代表要翻譯成簡中,只需要更改這兩個參數,就可以更改要翻譯的語言
再來要定位 input 和 output
input 比較簡單,整個頁面只有一個 textArea,所以也不需要特別定位
output 就比較麻煩,先按 F12,叫出 chrome dev tools (其他的瀏覽器也有對應的功能,這裏用 chrome),然後在翻譯的地方隨便打幾個字
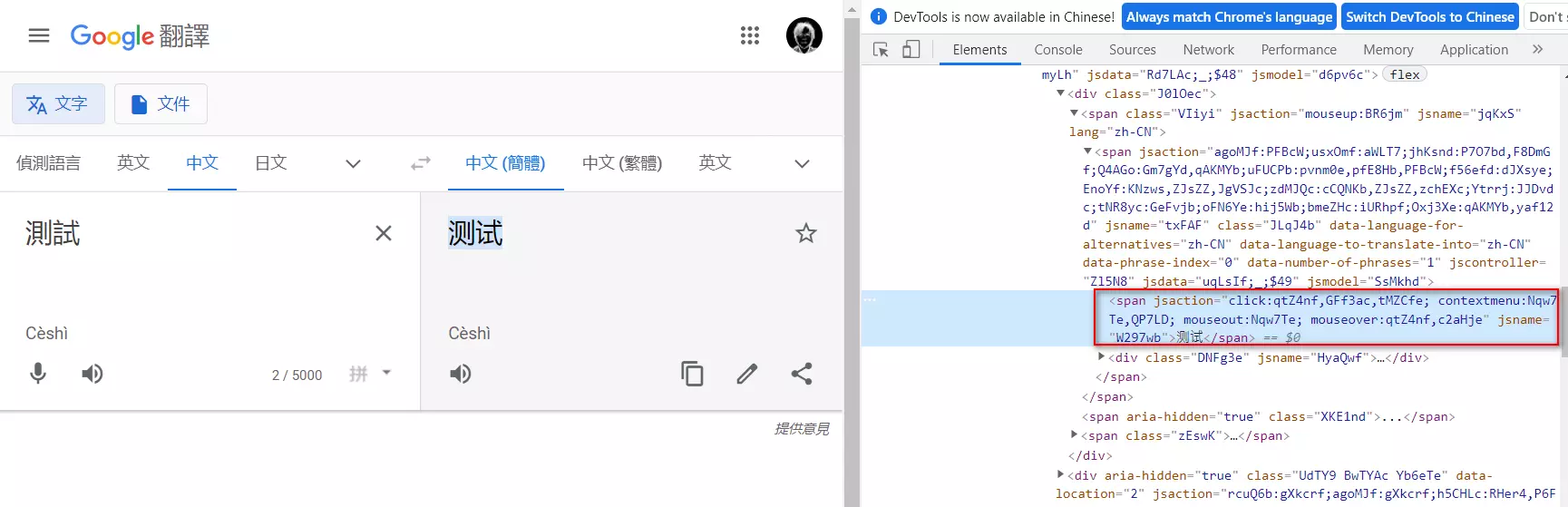
在對應的 span 按右鍵,選「Copy」再選「Copy Xpath」
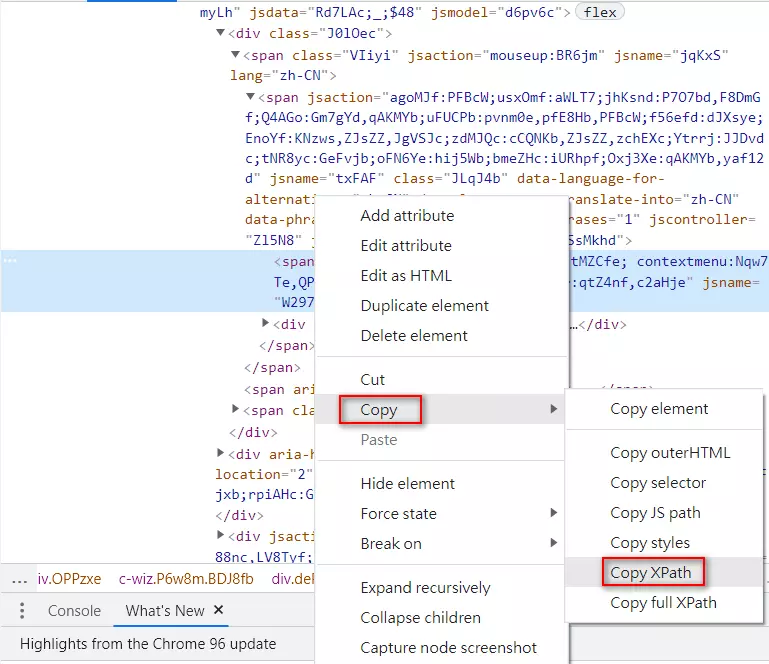
就會取得像以下的值
//*[@id="yDmH0d"]/c-wiz/div/div[2]/c-wiz/div[2]/c-wiz/div[1]/div[2]/div[2]/c-wiz[2]/div[5]/div/div[1]/span[1]/span/span
開始寫程式
安裝 Selenium
pip install selenium
設定的部份填上自己電腦環境的資料
- chrome_driver_path: 剛才下載 webdriver 後存放的路徑
- source_path: 翻譯檔案來源路徑
- target_path: 翻譯後檔案存放路徑
- translate_files: 要翻譯的檔案,可一次設定多個檔案
- source_language: 翻譯來源語言
- target_language: 翻譯後語言
- target_xpath: 剛才查到的 XPath
- sleep_second: 避免執行太頻繁,sleep 的秒數
完整程式碼如下
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
# Setting
chrome_driver_path = "C:/software/chromedriver_win32/chromedriver.exe"
source_path = 'C:/project/havocfuture/src/pages/'
target_path = 'C:/project/havocfuture/i18n/zh-hans/docusaurus-plugin-content-pages/'
translate_files = ['a.md', 'b.md']
source_language = 'zh-TW'
target_language = 'zh-CN'
target_xpath = '//*[@id="yDmH0d"]/c-wiz/div/div[2]/c-wiz/div[2]/c-wiz/div[1]/div[2]/div[2]/c-wiz[2]/div[5]/div/div[1]/span[1]/span/span'
sleep_second = 1
## 翻譯 function
def translate_text(_text):
url = "https://translate.google.com.tw/?sl=" + source_language + "&tl=" + target_language + "&op=translate"
options = webdriver.ChromeOptions()
options.add_argument("--no-sandbox")
options.add_argument("--headless")
options.add_argument('--disable-infobars')
options.add_argument('--blink-settings=imagesEnabled=false')
driver = webdriver.Chrome(executable_path=chrome_driver_path, options=options)
driver.get(url)
time.sleep(sleep_second)
input_element = driver.find_element_by_tag_name('textArea')
input_element.send_keys(_text)
time.sleep(sleep_second)
result_elements = driver.find_element_by_xpath(target_xpath)
result = result_elements.text
time.sleep(sleep_second)
driver.close()
return result
# 迴圈翻譯檔案
for x in translate_files:
source_file_path = source_path + x
target_file_path = target_path + x
f1 = open(source_file_path, 'r', encoding="utf-8")
source_content = f1.read()
f1.close()
f2 = open(target_file_path, 'w', encoding="utf-8")
target_content = translate_text(source_content)
f2.write(target_content)
f2.close()
這樣只要設定完後,執行後就可以一口氣就 Markdown 文檔翻譯完且放在對應的路徑下了
已知問題
google 翻譯頁面不能翻譯超過 5000 字元,如果檔案太大是會翻譯失敗的,如果有太大檔案的翻譯需求,看來還是要乖乖付錢去用 google translate API
googletrans
名字取得很像 google 官方的工具,但實際上是第三方的 lib,我是寫完上面使用 selenium 才發現這個工具的,怎麼使用可以參考官方文件,就不再多說
要注意的是直接用 pip install 的版本 3.0.0 我實測是不能用的,估計是 google 有改版,但原作者沒有繼續維護下去,改安裝社群修改過後的版本
pip install googletrans==3.1.0a0
實測 3.1.0a0 這個版本可以正常使用沒有問題
